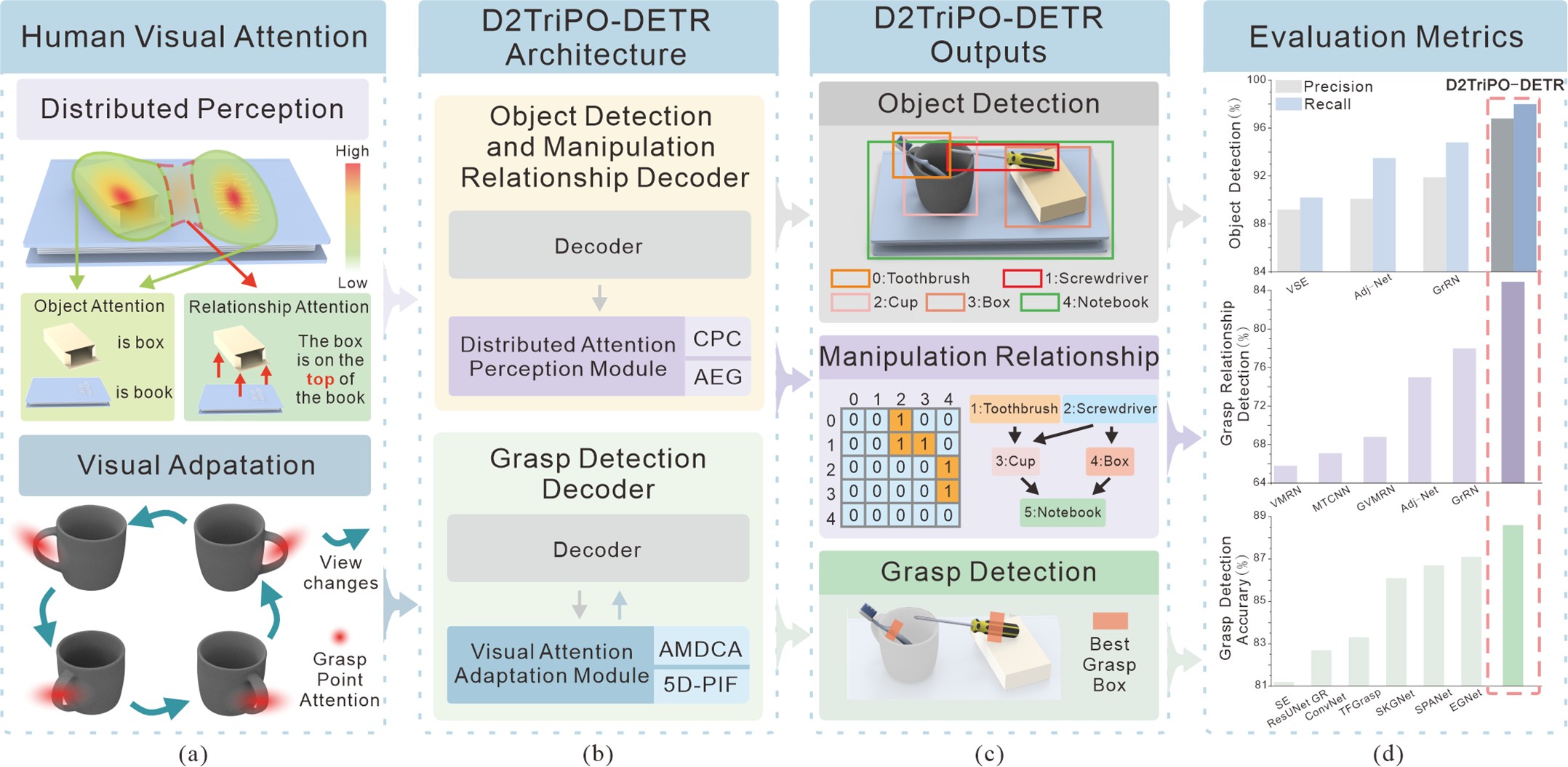
Experiment setup
描述文字(在此处填写关于 Fig. 7 的说明)。
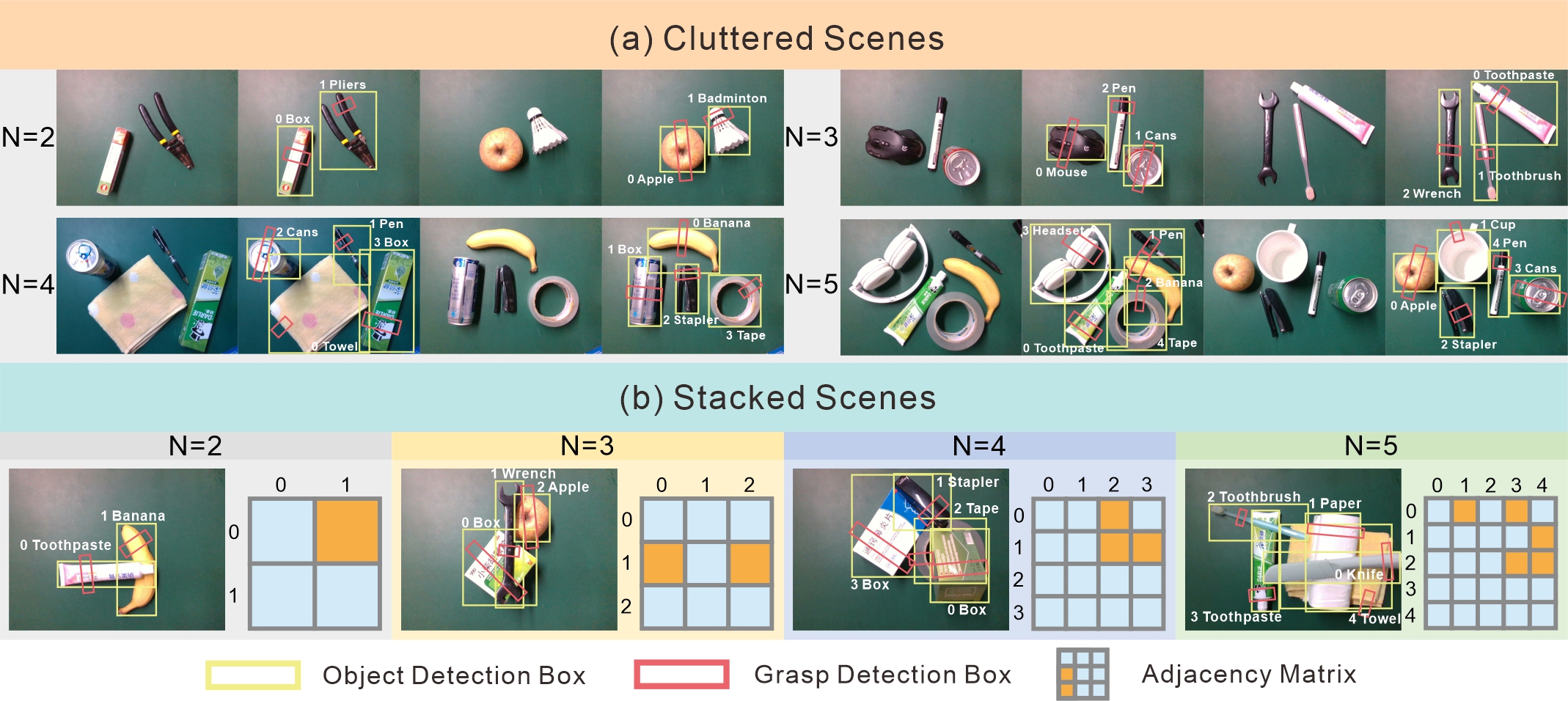
To evaluate applicability to real-world grasping, we test configurations with 2–5 objects. For each object count we run five trials in both cluttered and stacked settings, yielding 40 experiments in total.
Model results
| Models | Cluttered (%) | Stacked (%) |
|---|---|---|
| Mutli-Task CNN [8] | 90.60 | 65.65 |
| SMTNet [30] | 86.13 | 65.00 |
| EGNet [5] | 93.60 | 69.60 |
| D2TriPO-DETR (Ours) | 95.71 | 74.29 |
Per-object success rates
| Objects | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| Cluttered Scenes |
100.00% | 100.00% | 95.00% | 92.00% |
| Stacked Scenes |
90.00% | 73.33% | 75.00% | 68.00% |
Real-World Experiment
In the cluttered setting objects are placed separately to test detection among nearby items. The stacked setting introduces occlusions that require not only detection and grasp estimation but also reasoning about manipulation order to avoid failures. Our pipeline outputs detections, grasp candidates, and stacking relations in parallel; detections map to fixed queries to produce object indices and update an adjacency matrix P. If P is all-zero all objects are selectable; otherwise successive powers of P identify top-layer candidates. We keep grasp candidates with IoU > 0.5, rank them by confidence, and execute high-confidence candidates via inverse kinematics with closed-loop verification, updating P after each grasp–place cycle. D2TriPO-DETR shows superior relation recognition and sequence-planning, enabling robust ordered grasping in stacked scenes.
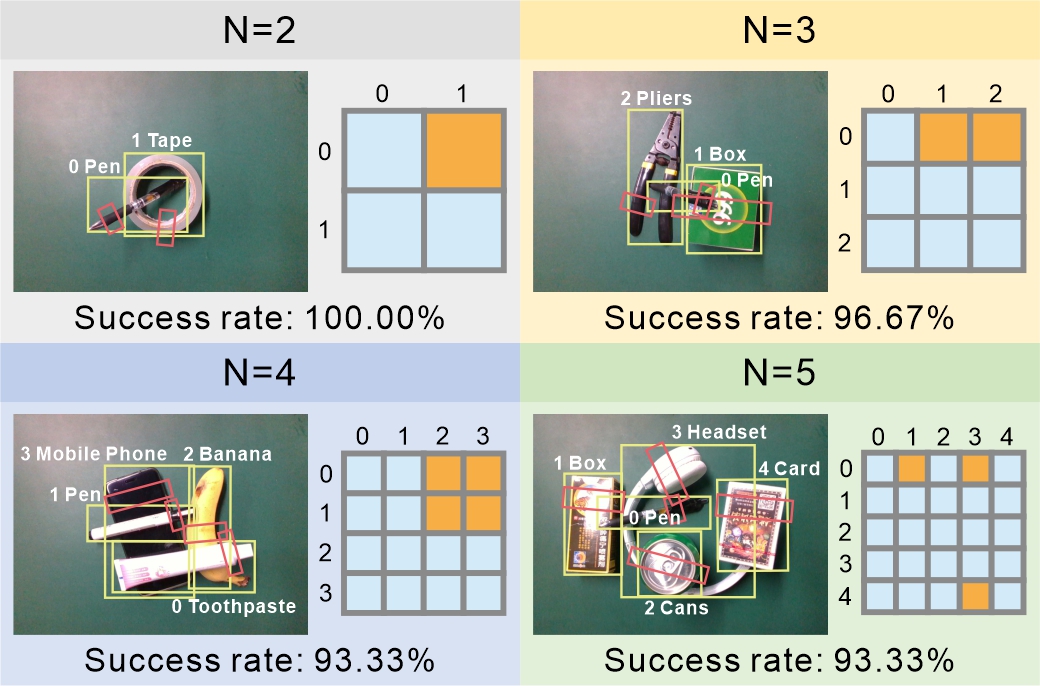
Stability evaluation
We selected representative scenarios with 2–5 objects and repeated each 30 times. The system shows only a modest drop in success rate as object count increases, maintaining high and stable performance across scales.
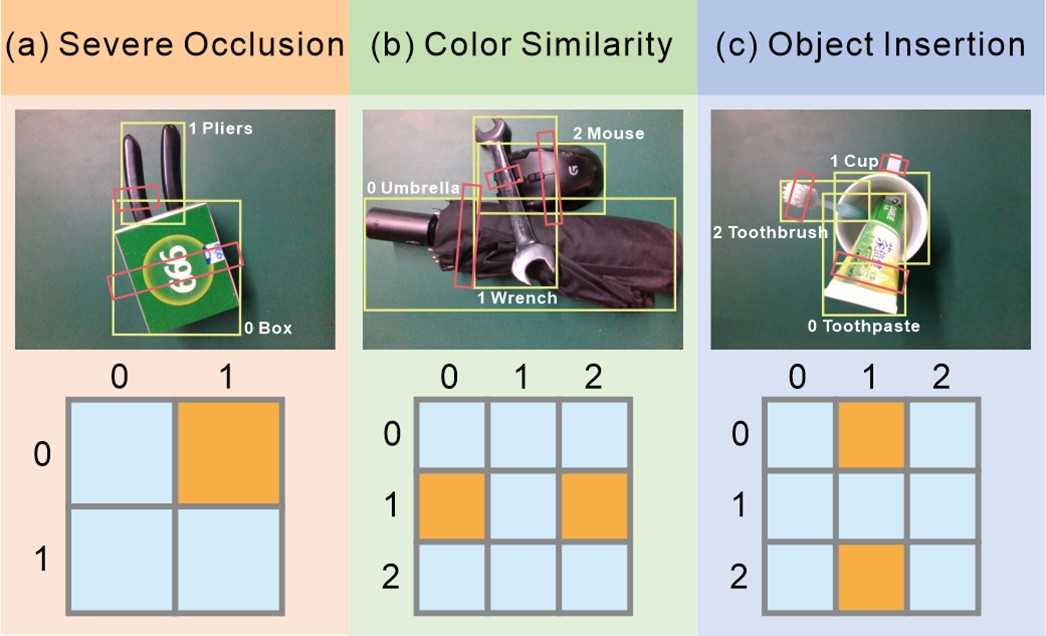
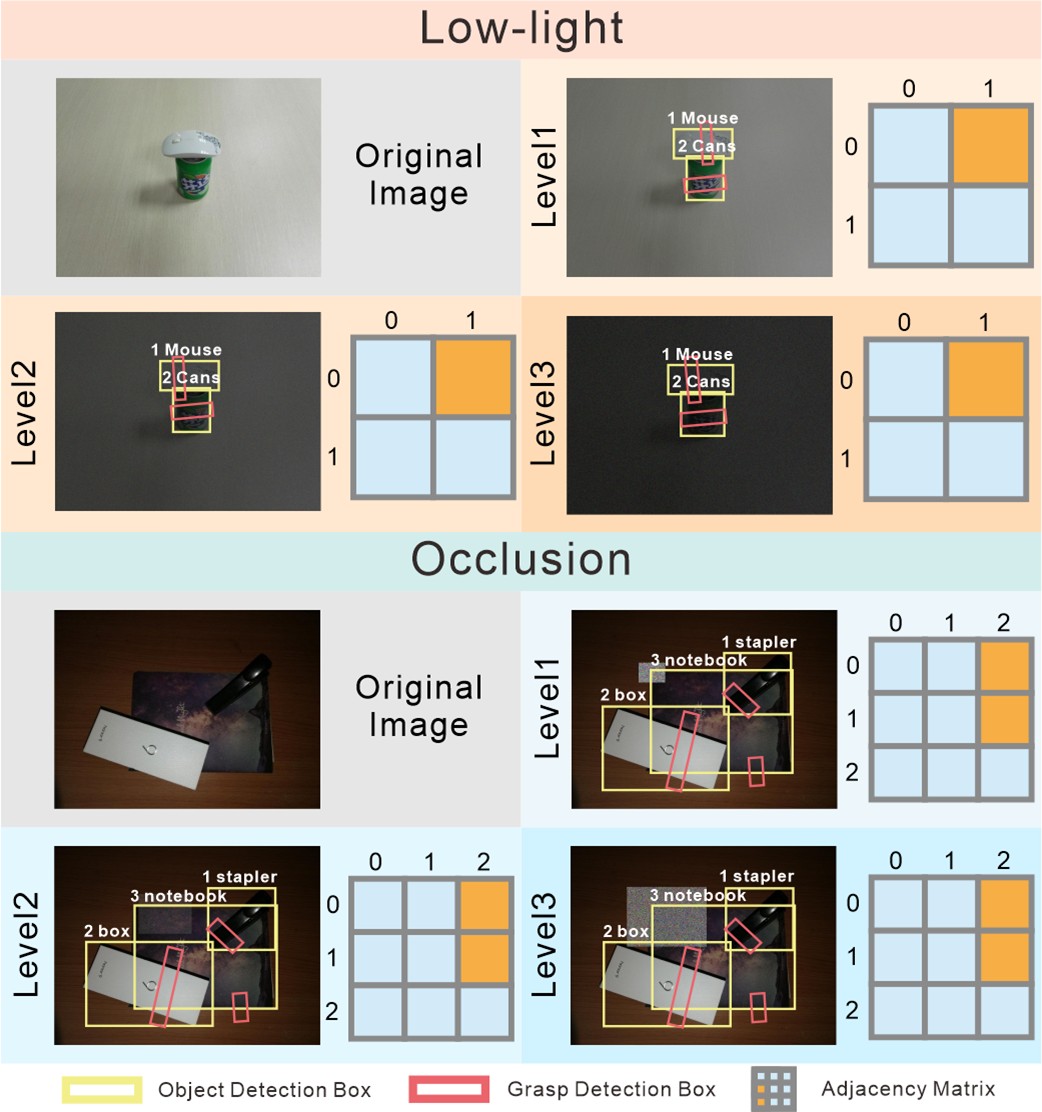
Robustness under boundary ambiguity
Under severe occlusion, similar colors, and insertion cases we observe grasp success rates of roughly 65%, 70%, and 60% respectively. Although boundary ambiguity reduces performance, the model still detects objects and infers stacking relations for most scenes, enabling successful grasps.
Demonstration video — real robot experiments